

TensorWave, AMD’nin MI300X modelinin NVIDIA’nın H100 modeline göre yapay zeka iş yüklerinde 3 kat daha yüksek performans gösterdiğini ortaya koyan son kıyaslamalarını yayınladı.
AMD MI300X, Yapay Zeka Karşılaştırmalarında NVIDIA H100’den 3 Kat Daha Hızlı
Yapay zeka bulut sağlayıcısı TensorWave, AMD’nin MI300 hızlandırıcısının NVIDIA H100 ile büyük dil modelli (LLM) yapay zeka kıyaslamalarında gösterdiği performansı sergiledi. AMD’nin sadece performans açısından değil, aynı zamanda maliyet-etkinliği açısından da öncü olabileceği belirtiliyor.
TensorWave’in blog yazısında yer alan bilgilere göre AMD’nin MI300 ve MK1 adlı yeni nesil hızlandırılmış yapay zeka motorları, Büyük Dil Modelleri (LLM) üzerinde optimize edilmiş performans sunarak işlem sürelerini önemli ölçüde kısaltıyor.
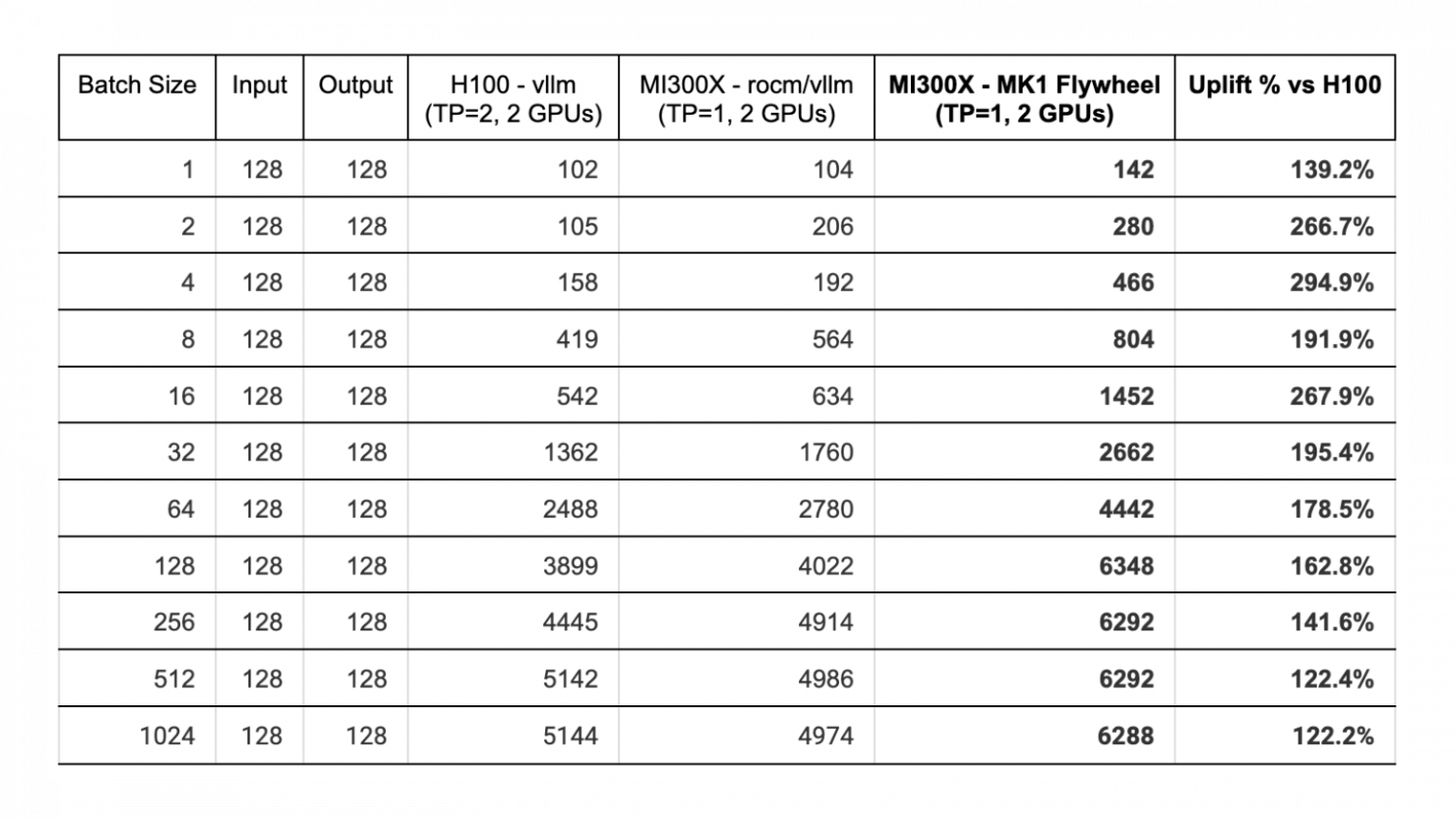
Şirket, Mixtral 8x7B modelini kullanarak AMD ve NVIDIA donanımları üzerinde çevrim içi ve çevrim dışı testler yaptı.
AMD’nin Donanım Özellikleri:
- Donanım: TensorWave işlem düğümü içeren 8 adet MI300X hızlandırıcı, 2 adet AMD EPYC işlemci (192 çekirdek), 2.3 TB DDR5 RAM.
- MI300X Hızlandırıcı: 192 GB VRAM, 5.3 TB/s bant genişliği, FP16 için yaklaşık 1300 TFLOPS.
- Sürücüler: ROCm 6.1.2
- Framework Yığını: MK1’in çıkarım motoru (Flywheel) v0.9.2 ve AMD’nin ROCm optimize edilmiş vLLM çatalı (rocm/vllm) v0.4.0
- Konfigürasyon: Mixtral 8x7B modeli tek bir MI300X’in 192 GB VRAM’ine sığacak şekilde ve tensör paralelliği 1 (tp=1) olarak ayarlandı.
NVIDIA’nın Donanım Özellikleri:
- Donanım: NVLink’li 8 adet H100 SXM5 hızlandırıcı, 160 CPU çekirdeği, 1.2 TB DDR5 RAM içeren baremetal işlem düğümü.
- H100 SXM5 Hızlandırıcı: 80 GB VRAM, 3.35 TB/s bant genişliği, FP16 için yaklaşık 986 TFLOPS.
- Sürücüler: CUDA 12.2
- Framework Yığını: vLLM v4.3
- Konfigürasyon: Mixtral 8x7B modeli iki H100’ün 80GB VRAM’ine sığacak şekilde tensör paralelliği 2 (tp=2) olarak ayarlandı.
Test Notları:
- Tüm kıyaslamalar, Mixtral 8x7B modeli kullanılarak yapıldı.
- Tüm Framework’ler, FP16 hesaplama yollarını kullanacak şekilde yapılandırıldı; FP8 hesaplama ise gelecekteki çalışmalara bırakıldı.
- Farklı tensör paralelliği ayarlarına sahip sistemler arasında doğru karşılaştırma yapabilmek için MI300X’in verimi iki katına çıkarıldı.
AMD’nin MI300X yapay zeka hızlandırıcısı, çevrim dışı performans testlerinde 1 ila 1024 arasında değişen boyutlarda NVIDIA H100’e göre %22 ila %194 arasında performans artışı gösterdi. MI300X, tüm boyutlarda H100 modelinden daha hızlı çalıştı.
Çevrim İçi Performans Temel Metrikleri:
- Üretilen İş (Saniye Başına İstek): Sistemin belirli bir iş yükü için saniyede işleyebileceği istek sayısı.
- Ortalama Gecikme Süresi (Saniye): Her istek için tam bir yanıt oluşturmak için ortalama geçen süre.
- Zaman Başına Üretilen Token (TPOT): İlk belirteçten sonraki her bir belirtecin üretilme süresi; bu, uzun yanıtların üretilme hızını etkiler.
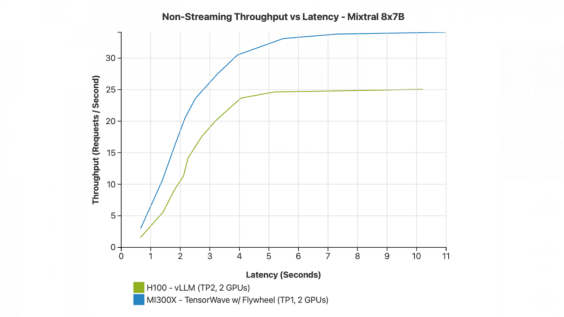
AMD’nin MI300X hızlandırıcısı, ortalama 5 saniyelik gecikme süresiyle iki NVIDIA H100 GPU’ya göre saniyede %33 daha fazla istek işleyebiliyor. Ayrıca H100’e kıyasla çok daha yüksek verimlilikle daha yüksek trafik hacimlerinde daha hızlı metin üretimi yapabiliyor.
Yapılan test sonrasında TensorWave, AMD’nin MI300X hızlandırıcılarının NVIDIA H100’e göre yüksek performansını ve rekabetçi fiyatını takdir etti. Şirketin CEO’su, MI300X’in H100’e kıyasla çok daha üstün bir seçenek olduğunu belirtti. Ayrıca genellikle zor bulunan H100’e kıyasla MI300X’in kolayca temin edilebileceği de ifade edildi.
Kaynak: wccftech.com







