

AMD, CDNA 4 mimarisini kullanan Instinct MI350 yapay zeka hızlandırıcısının tüm teknik ayrıntılarını Hot Chips 2025’te paylaştı. İki ay önce tanıtılan seri, büyük dil modellerinin hızla büyüyen ihtiyaçlarına odaklanıyor. Temel yaklaşım net: Veri türlerinde esneklik ve bellek ölçeğini büyütmek. HBM (Yüksek Bant Genişlikli Bellek) kapasitesi ve bant genişliği artıyor, bağlantılar hızlanıyor, güç verimliliği iyileşiyor.
MI350 Ailesi ve Mimari Özellikleri
Yeni ürünler, farklı veri türlerini destekleyerek hesaplama performansını artırıyor. Tam erişimli FP8’in yanı sıra mikro ölçekli MXFP6 ve MXFP4 desteği sunuluyor; bu sayede aynı güç seviyesinde daha yüksek hesaplama çıktısı elde edilebiliyor. Güç ve bağlantı tarafında ise un‑core güç tüketimi azaltılmış ve Infinity Fabric daha geniş bant ve verimli bir şekilde çalışıyor. Ürün gamında MI350X hava soğutmalı modeli, 1000W TBP ile 2.2 GHz’e kadar saat hızına sahipken sıvı soğutmalı MI355X; veri merkezleri için tasarlanmış, 1400W TBP ve 2.4 GHz’e kadar saat hızını destekliyor.


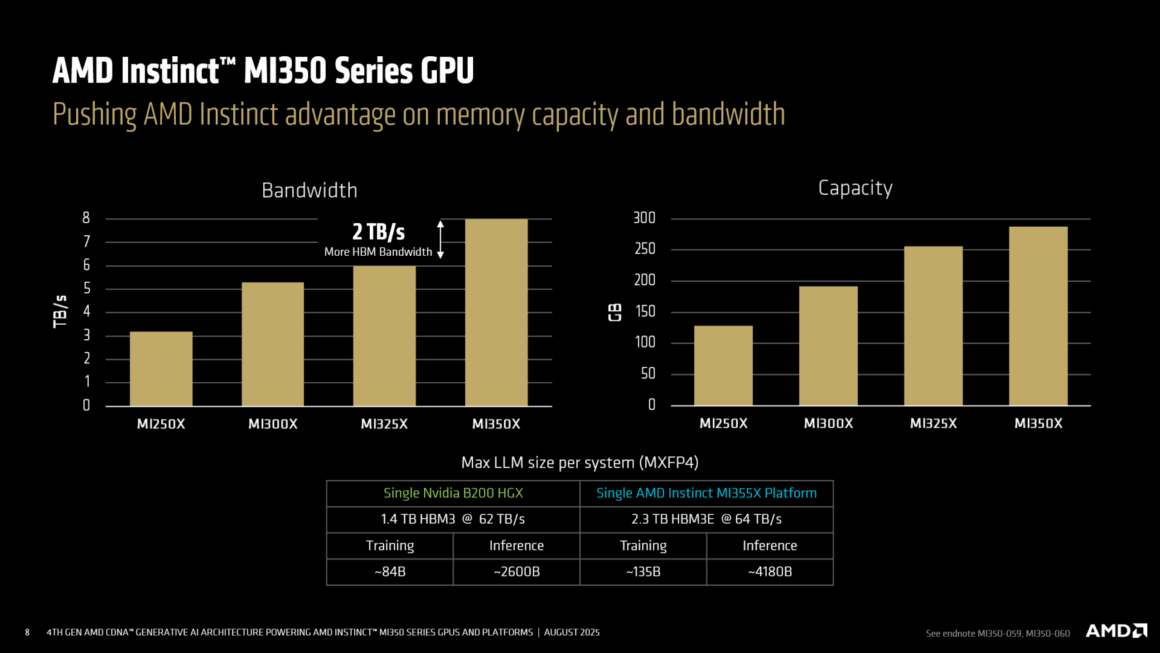
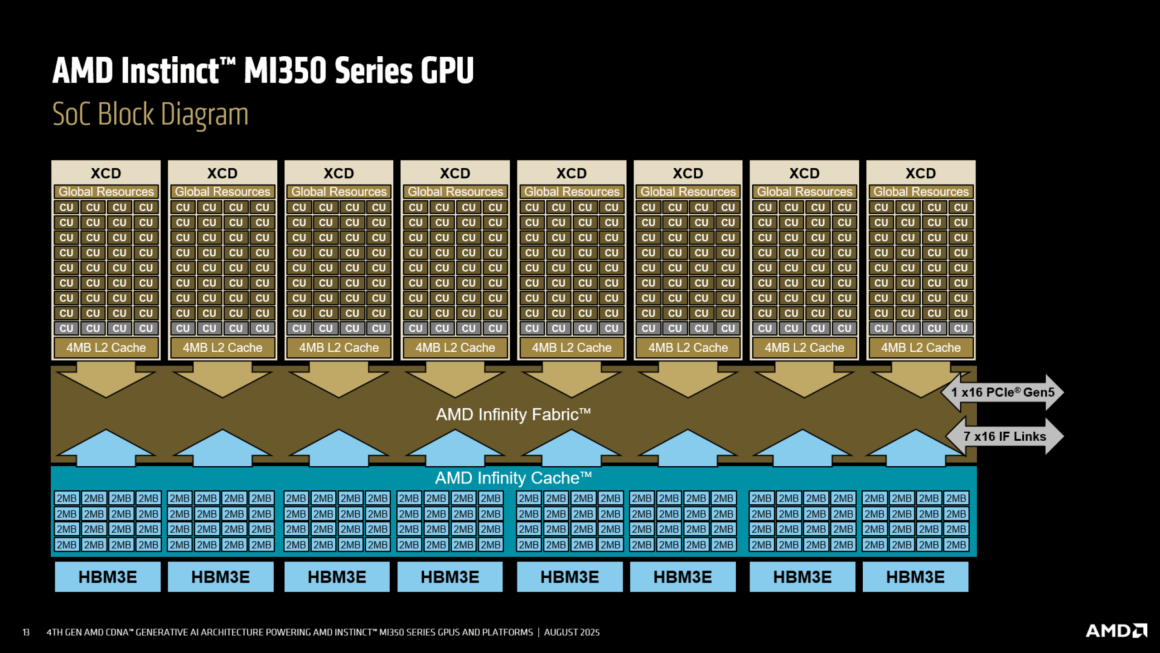
Yeni tasarım; 185 milyar transistör, 3D çok yongalı düzen ve HBM3e bellek ile dikkat çekiyor. TSMC’nin COWOS‑S paketlemesiyle üretilen yongada, 8 XCD (Accelerator Complex Die) ve 2 IOD (G/Ç Temel Yonga) bulunuyor. Her IOD, 3 Infinity Fabric bağlantısı ve bir PCIe Gen5 x16 hattı ile EPYC ana sisteme 128 GB/s hızında veri aktarımı sağlıyor. Dört HBM3e kontrolcüsü, 12‑Hi 36 GB’lık yığınlarla çalışıyor ve toplamda pakette 288 GB HBM3e bellek ile 8 TB/s’ye kadar bellek bant genişliği sunuluyor. İki IOD arasındaki Infinity Fabric AP bağlantısı, 5.5 TB/s ikiye ayrılmış bant genişliği sağlarken IOD üzerinde de 256 MB Infinity Cache bulunuyor. XCD’lere toplamda çift yönlü 1075 GB/s Infinity Fabric bant genişliği veriliyor.

Her XCD başına 32 CDNA 4 hesap birimi (CU) bulunuyor. Toplamda 256 CU ve her birinde 128 akış işlemcisi ile 16.384 genel çekirdek sağlanıyor. Ayrıca 1.024 Matris Çekirdeği (Matrix Core) mevcut. MI355X modelinde ise çekirdek hızı, 2.4 GHz’e kadar çıkabiliyor; bu da yüksek performans gerektiren görevler için ekstra hız sunuyor.
Dahili Bellek Hiyerarşisi
– Tüm yonga genelinde 131 MB vektör kayıtları.
– 40 MB LDS.
– 8 MB L1, 32 MB L2.
– 256 MB Infinity Cache (IOD üzerinde).

Ham Performans ve Veri Türlerine Göre Hızlar (AMD’nin MI355X, MI300X Karşılaştırması)
– Vector FP16: 157.3 TFLOPs (1.0x)
– Matrix FP16/BF16: 2.5 PFLOPs (1.9x)
– Matrix FP8: 5.0 PFLOPs (1.9x)
– Matrix INT8/INT4: 5.0 PFLOPs (1.9x)
– Matrix MXFP6/MXFP4: 10 PFLOPs (yeni)
– Vector FP32: 157.3 TFLOPs (1.0x)
– Vector FP64: 78.6 TFLOPs (1.0x)
– Matrix FP64: 78.6 TFLOPs (0.5x)
Her soketteki bellek iki kümeye ayrılabiliyor ve XCD’ler mantıksal GPU’lar olarak esnek biçimde bölünebiliyor. Bu sayede CPX+NPS2 teknolojisi ile aynı anda 8 adet 70 milyar parametreli model çalıştırmak mümkün oluyor. Ayrıca 8 hızlandırıcı arasındaki Infinity Fabric bağlantısı, çift yönlü 154 GB/s hıza ulaşıyor; bu da önceki nesle göre yaklaşık yüzde 20’lik bir performans artışı anlamına geliyor.
Yeni modül ve platform tasarımında yongalar, 3D paketleme ve montaj sürecinin ardından OAM (Open Accelerator Module) formatında soğutucularla birlikte sunuluyor. Bu OAM’ler, 8 hızlandırıcıya kadar destekleyen UBB 2.0 (Universal Base Board) kartlarına yerleştirilerek sunucu düğümlerine bağlanıyor ve hazır raf sistemlerine kolayca entegre edilebiliyor. Ayrıca 4U boyutundaki seçenekler, MI300X AC 750W ve MI325X AC 1000W gibi mevcut UBB8 altyapılarına sığacak şekilde tasarlanmış durumda.

AMD’ye göre MI350X platformu, maksimum 36.9 PF16/BF16 PFLOPs ve 73.9 PF8 PFLOPs hesaplama performansı sunuyor ve 10U boyutundaki hava soğutmalı yapılandırmalara kadar ölçeklenebiliyor. MI355X ise 40.2 PF16/BF16 PFLOPs ve 80.5 PF8 PFLOPs’a kadar performans sağlıyor ve 5U boyutundaki doğrudan sıvı soğutmalı (DLC) kasalara kadar ölçeklenebiliyor. Her iki platformda da 2.25 TB HBM3e bellek ve 1075 GB/s Infinity Fabric bant genişliği yer alıyor. Sunucu tarafında ise Zen 5 çekirdekli 5. nesil EPYC işlemciler ve Pensando UEC tabanlı NIC’ler kullanılıyor.

AMD’nin slaytlarına göre MI355X, NVIDIA’nın B200 ve GB200 modelleriyle karşılaştırıldığında bellek kapasitesinde 1.6 kat, bant genişliğinde ise eşit seviyede performans sunuyor. FP64 hesaplamalarında B200’e kıyasla 2.1 kat, GB200’e kıyasla 2 kat daha yüksek performans sağlanırken FP16 ve FP8’de hafif bir üstünlük, FP6’da ise B200 karşısında 2.2 kat ve GB200 karşısında 2 kat performans artışı gözlemleniyor. Ayrıca MI355X’in OAM çözümünün, GB200 SXM sistemlerine kıyasla yapay zeka ve yüksek performanslı hesaplamalarda (HPC) 2.1 kat daha yüksek ham hesap gücü sunduğu belirtiliyor.
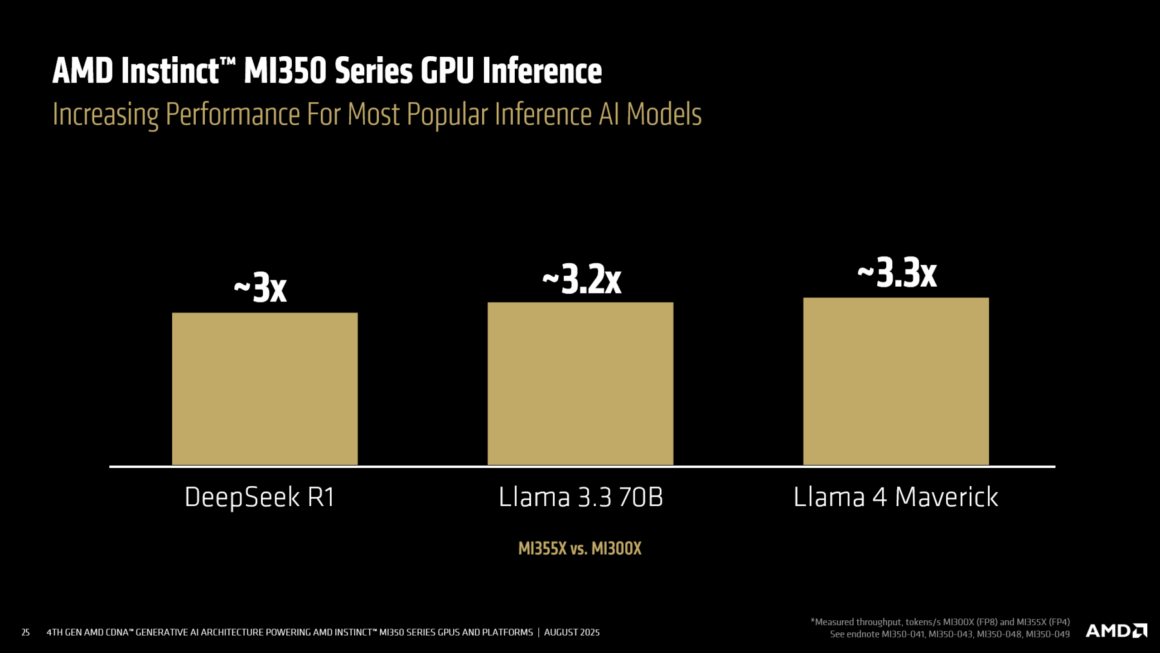
Gerçek iş yüklerine bakacak olursak AMD, Llama 3.1 405B ile çıkarım (throughput) tarafında MI300 serisine göre 35x artış gösteren bir grafik paylaştı. Büyük modeller için veri türü esnekliği ve HBM kapasitesi burada kritik rol oynuyor.

MI350 serisi, AMD’nin açıkladığına göre 2025’in üçüncü çeyreğinde iş ortaklarının sistemlerinde yaygın biçimde yer alacak. Bir sonraki nesil MI400 serisi ise 2026’da planlanıyor.
Sonuç olarak Instinct MI350 ailesi, büyük modeller için bellek ölçeği, veri türü esnekliği ve bağlantı tarafında anlamlı iyileştirmeler getiriyor. Hava ve sıvı soğutmalı hazır platformlarla birlikte veri merkezleri için hem eğitim hem çıkarım tarafında daha yüksek performans ve daha iyi verimlilik hedefleniyor.
Kaynak: wccftech.com