

Intel, Meta’nın en yeni yapay zeka modeli Llama 3 GenAI iş yükleri için optimize edilmiş Xeon, Core Ultra, Arc ve Gaudi ürün serilerini tanıttı.
Intel; Meta’nın en yeni yapay zeka modeli Llama 3 GenAI iş yükleri için optimize ettiği Xeon ve Core Ultra CPU’ları, Arc GPU’ları ve Gaudi hızlandırıcıları dahil olmak üzere ürün gamını doğruladı ve performans testlerini gerçekleştirdi
Basın açıklaması şu şekilde: Meta, bugün yeni nesil büyük dil modeli (LLM- Large Language Model) olan Meta Llama 3’ün lansmanını gerçekleştirdi. Intel lansman günü itibariyle kullanıma hazır olacak Gaudi hızlandırıcıları, Xeon ve Core Ultra işlemcileri ve Arc GPU’larının Llama 3 8B ve 70B modelleri için doğrulandığını ifade etti.
Peki bu neden haber değeri taşıyor? Yapay zekayı her yere taşıma misyonunun bir parçası olarak Intel, ürünlerinin dinamik yapay zeka alanındaki en son yeniliklere hazır olmasını sağlamak için yazılım ve yapay zeka ekosistemine yatırım yapıyor. Veri merkezindeki Gelişmiş Matris Uzantısı (AMX- Advanced Matrix Extension) hızlandırıcılı Gaudi ve Xeon işlemciler, müşterilere dinamik ve geniş kapsamlı gereksinimleri karşılama opsiyonları sunuyor.
Intel Core Ultra işlemciler ve Arc grafik ürünleri, yerel araştırma ve geliştirme için kullanılan PyTorch ve PyTorch için Intel Uzantısı ve model geliştirme ve çıkarım için kullanılan OpenVINO araç seti dahil olmak üzere kapsamlı yazılım kütüphane ve araçları desteğiyle hem yerel bir geliştirme aracı sunuyor hem de milyonlarca cihaza yayılabilme olanağı sağlıyor.
Intel üzerinde çalışan Llama 3 hakkında: Intel, Llama 3’ün 8B ve 70B parametreli modelleri için yaptığı ilk testlerde ve performans değerlendirmelerinde en yeni yazılım optimizasyonlarını sağlamak amacıyla PyTorch, DeepSpeed, Optimum Habana kütüphanesi ve PyTorch için Intel Uzantısı gibi açık kaynaklı yazılımları kullandı.
- Intel Gaudi 2 hızlandırıcıları, Llama 2 modelleri üzerinde (7B, 13B ve 70B parametreleri) optimize edilmiş performans gösterdi ve şimdi de yeni Llama 3 modeli için ilk performans ölçümlerine sahip. Gaudi yazılımının olgunlaşmasıyla birlikte Intel, yeni Llama 3 modelini rahatlıkla çalıştırıp çıkarım ve hassas ayarlar için sonuçlar elde etti. Llama 3, yakın zamanda duyurulan Gaudi 3 hızlandırıcısı tarafından da destekleniyor.
- Intel Xeon işlemciler zorlu uçtan uca yapay zeka iş yüklerine hitap ediyor ve Intel gecikmeyi azaltmak amacıyla LLM sonuçlarını optimize etmek için yatırım yapıyor. Performans çekirdekli Xeon 6 işlemciler (kod adı Granite Rapids), 4. Nesil Xeon işlemcilere kıyasla Llama 3 8B çıkarım gecikmesinde 2 kat iyileşme ve Llama 3 70B gibi daha büyük dil modellerini, oluşturulan token başına 100 ms’nin altında çalıştırma yeteneği gösteriyor.
- Intel Core Ultra ve Arc Graphics, Llama 3 için etkileyici bir performans sunuyor. İlk test aşamasında Core Ultra işlemciler şimdiden sıradan bir insanın okuma hızından daha yüksek okuma hızları sağlıyor. Öte yandan Arc A770 GPU, LLM için Xe Matrix eXtensions (XMX) ve 16GB özel belleğe sahip, bu da LLM iş yükleri için olağanüstü bir performans sağlıyor.
Xeon Ölçeklenebilir İşlemciler
Intel, Xeon platformları için LLM çıkarımını devamlı olarak optimize ediyordu. Örnek vermek gerekirse, Llama 2 ile karşılaştırıldığında PyTorch ve PyTorch için Intel Uzantısı’ndaki yazılım iyileştirmeleri 5 kat gecikme azalması sağlayacak şekilde geliştirildi. Yapılan iyileştirmeler, mevcut hesaplama kullanımını ve bellek bant genişliğini en üst düzeye çıkarmak için “paged attention” ve “tensor parallel”den (büyük dil modellerinin eğitim ve çalışma süresini iyileştirmesine yardımcı olan teknikler) yararlanıyor.
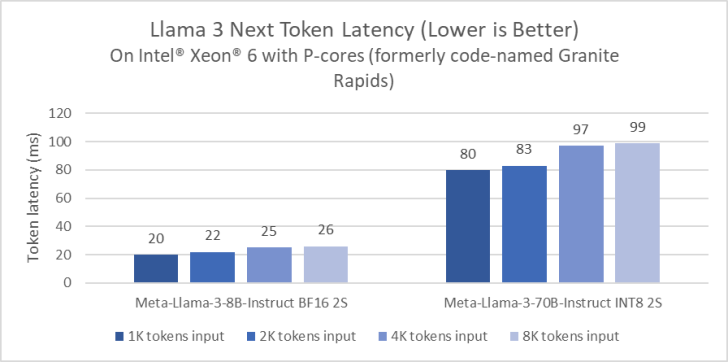
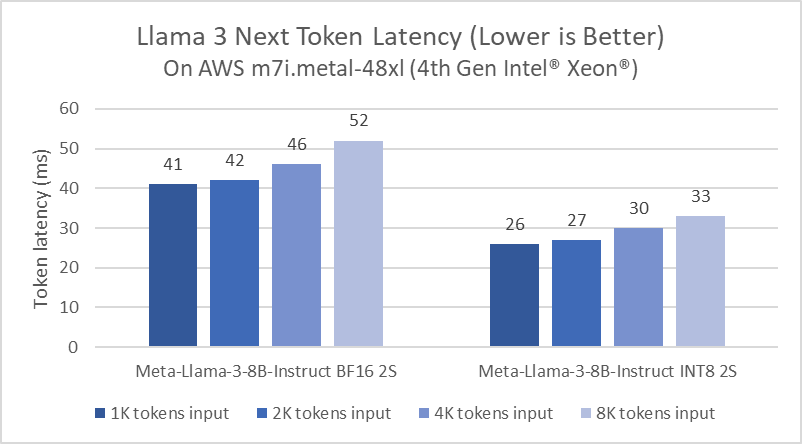
Performansın bir ön izlemesini paylaşmak için Meta Llama 3 Performans çekirdekli bir Xeon 6 işlemci (eski kod adı Granite Rapids) üzerinde kıyaslandı. Bu ön izleme rakamları Xeon 6’nın Llama 3 8B çıkarım gecikmesinde, yaygın olarak bulunan 4. Nesil Xeon işlemcilere kıyasla 2 kat iyileşme sağladığını ve tek bir çift soketli sunucuda Llama 3 70B gibi daha büyük dil modellerini üretilen her token için 100 milisaniyenin altında çalıştırabildiğini gösteriyor.
| Model | TP | Hassasiyet | Girdi Uzunluğu | Çıkış Uzunluğu | Verimlilik | Gecikme | Batch |
|---|---|---|---|---|---|---|---|
| Meta-Llama-3-8B-Instruct | 1 | fp8 | 2.000 | 4.000 | 1549.27 token/saniye | 7.747 ms | 12 |
| Meta-Llama-3-8B-Instruct | 1 | bf16 | 1.000 | 3.000 | 469.11 token/saniye | 8.527 ms | 4 |
| Meta-Llama-3-70B-Instruct | 8 | fp8 | 2.000 | 4.000 | 4927.31 token/saniye | 56.23 ms | 277 |
| Meta-Llama-3-70B-Instruct | 8 | bf16 | 2.000 | 2.000 | 3574.81 token/saniye | 60.425 ms | 216 |
İstemci Platformları
İlk değerlendirme aşamasında Intel Core Ultra işlemci şimdiden tipik insan okuma hızlarından daha yüksek okuma hızları elde etti. Bu sonuçlar, 8 Xe-çekirdekli dahili Arc GPU, DP4a AI hızlandırma ve 120 GB/s’ye kadar sistem belleği bant genişliği ile destekleniyor. Özellikle yeni nesil işlemcilerimize geçerken, Llama 3’te devam eden performans ve güç verimliliği optimizasyonlarına yatırım yapmaktan heyecan duyuyoruz.

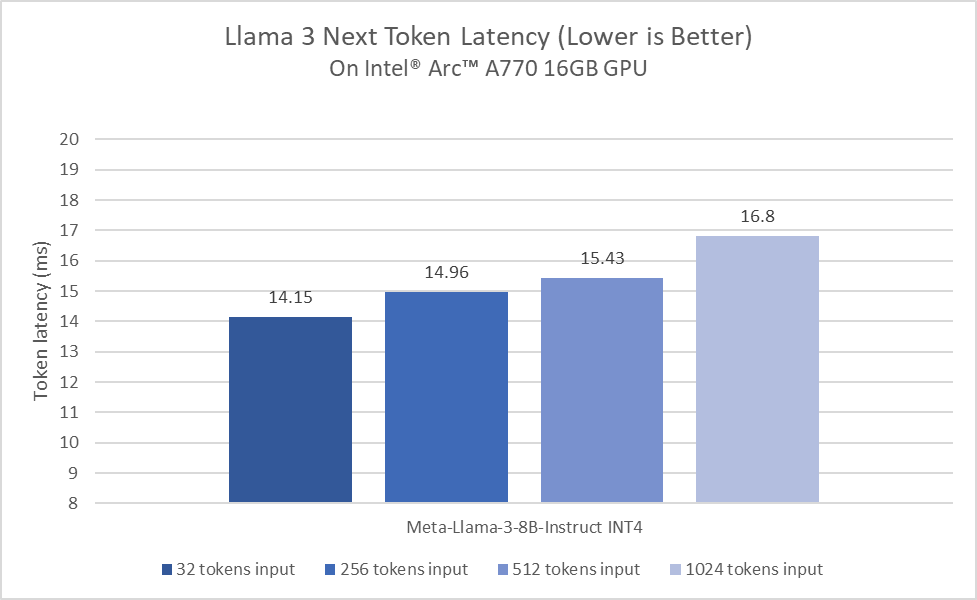
Intel ve Meta arasındaki iş birliği, lansman günü itibariyle hem Core Ultra işlemciler hem de Arc grafik ürünleri desteğiyle, yerel geliştirme platformu ve milyonlarca cihaza dağıtım imkanı sunuyor. Intel’in istemci donanımları, kapsamlı yazılım kütüphaneleri ve çeşitli araçlar sayesinde hızlandırılıyor. Bunlar arasında yerel araştırma ve geliştirme için kullanılan PyTorch ve PyTorch için Intel Uzantısı ile model dağıtımı ve çıkarım için kullanılan OpenVINO araç seti yer alıyor.
Sırada ne var? Meta’nın önümüzdeki aylarda LLM’ini yeni yetenekler, ek model boyutları ve gelişmiş performans ile geliştirmesi bekleniyor. Intel ise bu yeni LLM’yi desteklemek için yapay zeka ürünlerinin performansını optimize etmeye devam edecek.
Kaynak: wccftech.com