
Google Research, büyük dil modelleri (LLM) ve vektör arama sistemleri için geliştirilen yeni nesil sıkıştırma algoritması “TurboQuant”ı duyurdu. Şirket, bu teknolojinin yapay zekâ sistemlerinde hem bellek kullanımını radikal biçimde azaltacağını hem de performansı ciddi ölçüde artıracağını belirtiyor.
TurboQuant ile Bellek Kullanımı 6 Kat Azalıyor, Hız 8 Kat Artıyor
Yapay zekâ modelleri, verileri anlamak ve işlemek için “vektör” adı verilen matematiksel temsilleri kullanıyor. Özellikle yüksek boyutlu vektörler; metinlerin anlamını, görsellerin özelliklerini veya büyük veri kümelerinin yapısını analiz edebilse de oldukça yüksek bellek tüketimine yol açıyor. Bu durum, modellerin en kritik bileşenlerinden biri olan “key-value cache” (anahtar-değer önbelleği) üzerinde darboğaz oluşturarak performansı sınırlıyor.
TurboQuant, bu sorunu çözmek için gelişmiş örnekleme (quantization) tekniklerini kullanıyor. Geleneksel vektör sıkıştırma yöntemleri genellikle ek bellek yükü oluştururken, TurboQuant bu “gizli maliyeti” ortadan kaldıracak şekilde tasarlanmış durumda. Sistem, veriyi daha verimli temsil ederken doğruluk kaybı yaşanmamasını sağlıyor.
Teknolojinin temelinde iki önemli yöntem bulunuyor: PolarQuant ve QJL (Quantized Johnson-Lindenstrauss). PolarQuant, veriyi farklı bir koordinat sistemine dönüştürerek sıkıştırmayı daha verimli hâle getirirken QJL algoritması, yalnızca 1 bitlik ek veri kullanarak oluşabilecek hataları ortadan kaldırıyor. Bu sayede model, yüksek doğruluğunu korurken çok daha az bellekle çalışabiliyor.
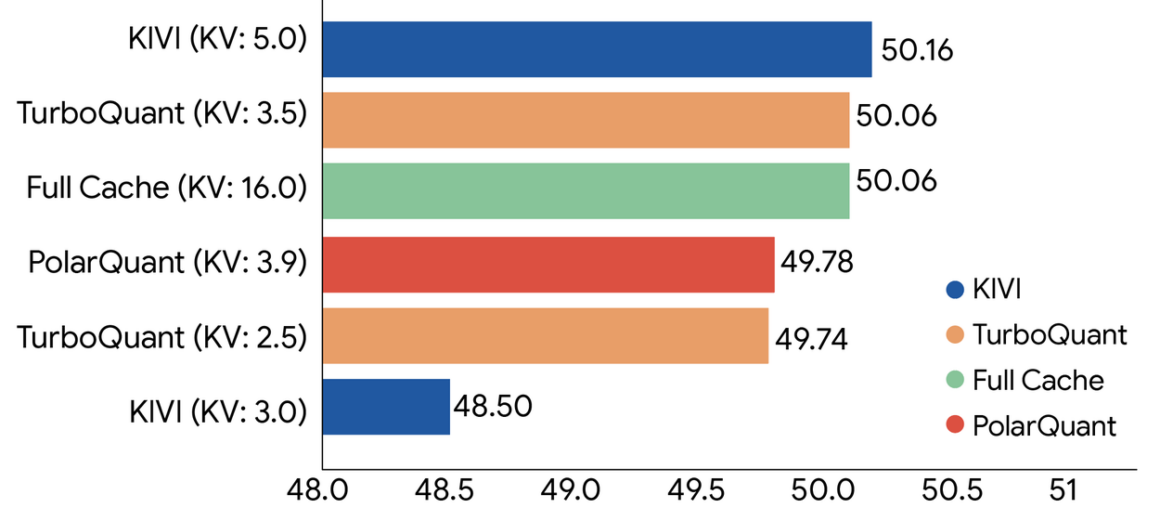
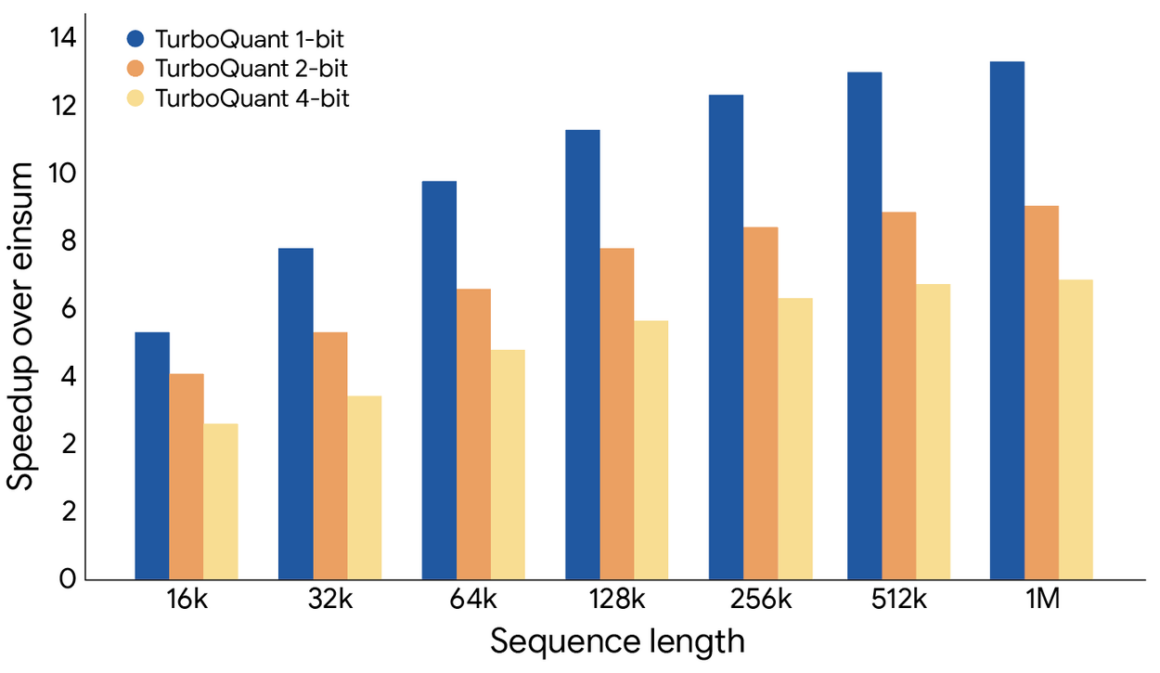
Google’ın paylaştığı test sonuçlarına göre TurboQuant, anahtar-değer önbelleği boyutunu en az 6 kat küçültürken işlem performansını da 8 kata kadar artırabiliyor. Üstelik bu kazanımlar, model doğruluğunda herhangi bir kayıp olmadan elde ediliyor. Teknolojinin, Gemma ve Mistral gibi açık kaynaklı modeller üzerinde yapılan testlerde de başarılı sonuçlar verdiği belirtiliyor.
Örnek vermek gerekirse dev bir fotoğraf dosyası, bir sıkıştırma aracıyla 6’da 1 boyutuna indiriliyor fakat fotoğraf açıldığında görüntüde hiçbir bulanıklık veya detay kaybı olmuyor.
Bu gelişme, yalnızca sohbet tabanlı yapay zekâları değil, aynı zamanda modern arama motorlarını da doğrudan etkileyebilir. Vektör arama teknolojisi sayesinde sistemler, artık sadece anahtar kelimeler yerine kullanıcı niyetini ve anlamı da analiz edebiliyor. TurboQuant ise bu tür büyük ölçekli arama sistemlerinin daha hızlı, daha düşük maliyetli ve daha verimli çalışmasını mümkün kılıyor.
Kısacası TurboQuant, güçlü teorik temellere dayanan algoritmik bir yenilik. Yapay zekânın giderek daha fazla alana entegre edildiği günümüzde bu tür temel optimizasyonlar, gelecekte uygulamaları daha hızlı, daha erişilebilir ve daha ekonomik hâle getirebilir.
Kaynak: Google Research







